- Let's talk about a new ADT, or rather an extension of the old ADT,
Maps. These extensions are called Ordered Maps.
- An ordered map is just like a Map, but it has some additional
operations:
- first() - returns the element with the smallest key,
- last()- returns the element with the largest key,
- next(k) returns the element with the smallest key larger than k, and
- prev(k)- returns the element with the largest key smaller than
k.
- OK, let's look at the naive implementations: Unsorted Array,
Sorted Array, Unsorted Linked-List:
| | Unsorted Array | Sorted Array | Unsorted Linked List |
| insert(k,e) | O(1) | O(n) | O(1) |
| get(k) | O(n) | O(lg n) | O(n) |
| remove(k) | O(n) | O(n) | O(n) |
| first() | O(n) | O(1) | O(n) |
| last() | O(n) | O(1) | O(n) |
| next(k) | O(n) | O(lg n) | O(n) |
| prev(k) | O(n) | O(lg n) | O(n) |
- What about hashtables? Their performance is the same as the
unsorted structures above.
- So hashtables are good implementations of Maps but they have three
weaknesses, they have poor worst case bounds, they may require
resizes, making them poor at real time tasks, and they're not good
at ordered Map operations
- What we want is a linked structure (for easy inserts/deletes) but
that has log(n) finds.
- Linked structure.... log(n)....we want trees! Binary Search
Trees, to be precise.
- A BST is a binary tree where an item (and key) is stored at each
node. it has the following 2 properties:
- ∀n,m LeftDescendant(m,n) → key(m) < key(n)
- ∀n,m rightDescendant(m,n) → key(m) > key(n)
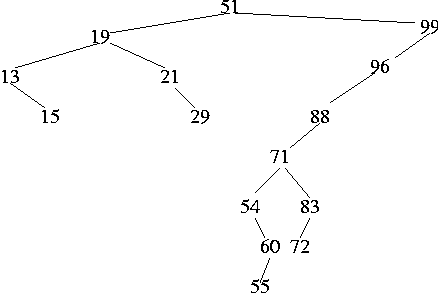
- Lets try one with the following set of numbers:
51 19 99 96 13 15 21 88 71 54 60 55 83 29 72
def get(k):
return search(k,root()).data
def search(k,v):
if v is None:
return v
if key(v)==k:
return v
if k < key(v):
return search(k,left(v))
if k > key(v):
return search(k,right(v))
- How long does that take (in terms of the height of the tree)?
O(h). More about this later.
- OK, what about insert? We find the leaf where it is supposed to
go, and then we put it there:
insert(key,value):
root = insert_rec(root,key,value)
insert_rec(node,key,value):
if node is None:
return new Node(key,value)
elif key< node.key:
node.left = insert_rec(node.left,key,value)
elif key > node.key:
node.right = insert_rec(node.right,key,value)
elif key == node.key:
node.value = value
return node
- This also takes O(h).
- Deleting is trickier. Our cases are:
- We're deleting something with no children. That's easy-
We just remove it
- We're deleting something with only one child, such as 88.
We just delete it and replace it with the child
- We're deleting something with two children, such as 51. We want to
alter the tree as little as possible, right? Could we find a node to
swap with 51 that would require no tree restructuring?
(E.G. swapping with 71 would not work) Either 29 or 54.
- What if we were deleting 71? Either 60 or 72.
- What do these nodes have in common? They are the next highest or
lowest k in the tree. It doesn't matter which we pick, so lets
go with the next highest.
- Why does that work? well, all right descendants are greater than
k, but the left-most has nothing less than it in its part of the
tree. It is the next key up. Thus swapping with it shouldn't change
the tree.
- So what do we do?
remove(key):
root = remove_rec(root,key)
remove_rec(node,key):
#base case, we've walked off the end of the tree, key is not here
if not node:
return node
#go left or right as appropriate in the search for the key
if key < node.key:
node.left = remove_rec(node.left, key)
# If the key is larger than the current_node's key, then it's in the right subtree
elif key > node.key:
node.right = remove_rec(node.right, key)
# This is the node to be deleted
else:
#if the node has only one child:
if not node.left:
return node.right
elif not node.right:
return node.left
#two children, swap with next_node:
else:
#first, swap
next = next_node(node)
node.key = next.key
node.value = next.value
#Now we need to go delete that other node whose data we just moved up here
node.right = remove_rec(node.right, node.key)
#notice we change the key we're looking for
- whew.
- Oh, wait, what is next_node()?
def rightThenLeftMost(v):
return leftMost(right(v))
def leftMost(v)
if left(v) is None:
return v
return leftMost(left(v))
- OK, how long does this take? O(h)!
- Why does it find the next largest than v?
- Everything to the right of v is larger than v.
- if v is a left child of parent(v) then key(parent(v)) > key(v). But if v
has a right child then key(right(v)) < key(parent(v), so the next
largest must be in that subtree.
- The smallest node in a subtree is the leftmost node.
- And by the way, the leftmost node can have no left child, so it can be deleted
easily.
- Given what we know now, finding next(k) shouldn`t be too bad:
- first we need to find(k).
- if that node has a right child, then next is just the
rightThenLeftMost descendant.
- But what if there is no right child?
- Then the next highest is the first ancestor that is to the right:
def next(k):
n = get(k)
if n is None:
return None
if n.right is None
return greater_ancestor(n)
else:
return rightThenLeftMost(v)
where...
def greater_ancestor(n):
return greater_a(n, root, None)
def greater_a(current, node, successor):
if not current:
return successor
if node.value < current.value:
# Current node is a potential successor, search in the left subtree
return find_successor_recursive(current.left, node, current)
elif node.value > current.value:
# Continue searching in the right subtree
return find_successor_recursive(current.right, node, successor)
else:
# Node is found, return the current successor
return successor
- The only thing left is previous, which is just the opposite of
next()
- And thus next takes O(h).
