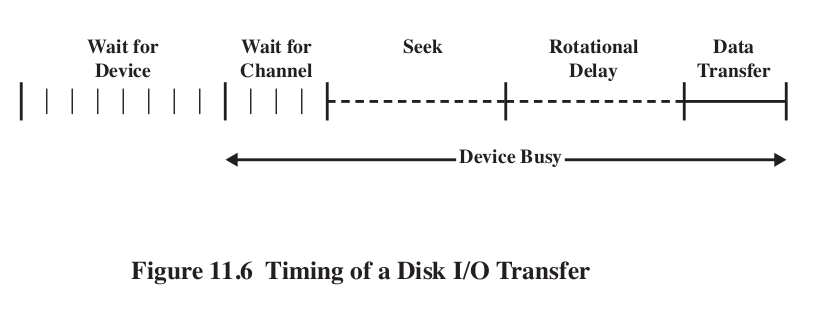
\[ T=\frac{b}{rN} \] Where T is transfer time, b is number of bytes, r rotation speed, N is number of bytes in track. \[ T_a = T_s + \frac{1}{2r}+\frac{b}{rN} \] This equation shows the penalty for accessing arbitrary locations on disk.
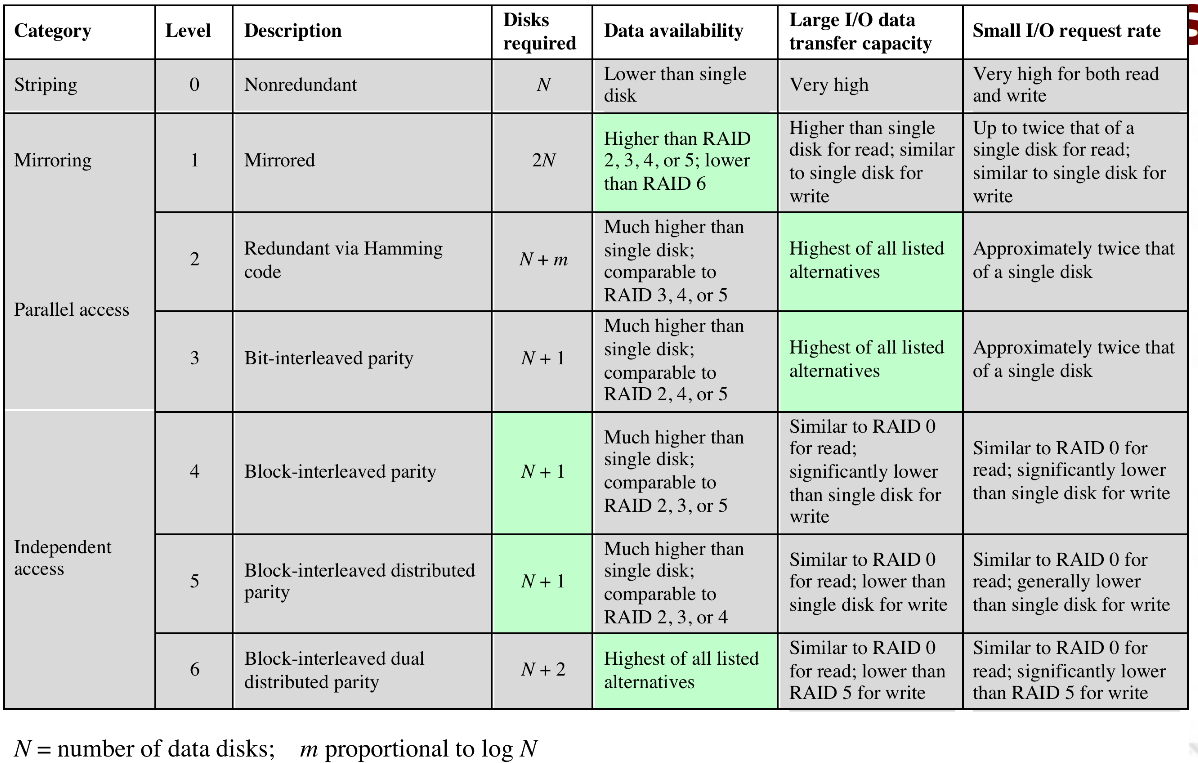
- It stands for redundant array of inexpensive disks. The basic ideas is that with multiple disks, we can parallelize our reads.
- But in this case locality is not our friend. If we spread our data across many disks, then at any one time we might be reading from just one of them anyway.
- Instead, we make the disks redundant repeating on the multiple disks.
- More disks means more disks likely to break. We must manage that.
- RAIDs can be executing in a number of ways, traditionally referred to as 'levels' 0-6.
- RAID 0:
- Not really a RAID. Data is spread across all the disks, no redundancy.
- But data is not just spread around, it
is striped. This helps with our locality. Making
the strips small helps.
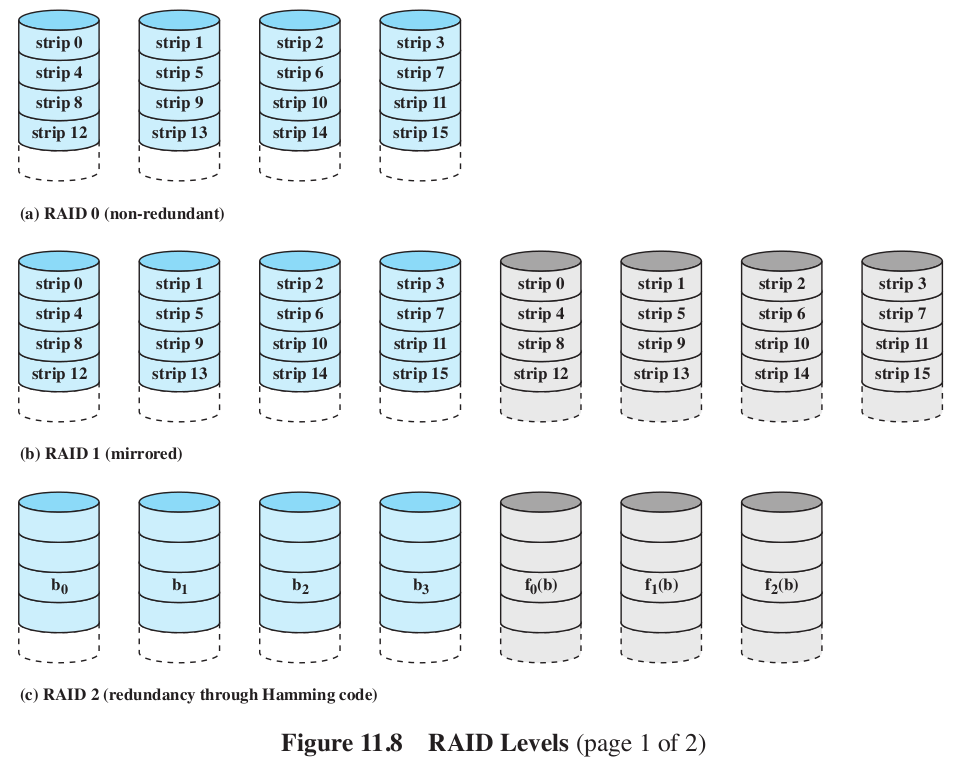
- Level 1: Mirrored.
- This gives us some parallelism. Writes have to be done on both disks. Failure recovery is easy.
- Is however, expensive.
- Level 2: Hamming code.
- All disks participate in every read. Stripes are super small (like a byte or 4).
- Use some of the disks to store the Hamming code for the
stripe.
- Insert extra bits at positions that are powers of 2: 1,2,4,8,16,32. Values at those positions are computed as parities of the subset of bits:
- \(h_1(w)\) computes the parity of every other bit in the word: 1,3,5,7,9,...
- \(h_2(w)\) 2,3,6,7,10,11,...
- \(h_4(w)\) 4,5,6,7,12,13,14,15,...
- \(h_8(w)\) 8-15,24-31,...
- 011100101110 has a bit flipped. Where?
- still requires \(\log_2 w\) extra space.
- Level 3:
- Similar to RAID 2, but with just 1 redundant disk.
- Parity bit set on the redundant disk based on xor of the bits on the other disks: \(X_r(i) = X_1(i) \oplus X_2(i) \oplus X_3(i) \oplus ... \)
- if disk 3 goes bad, when we replace it, we recompute its bits: \(X_3(i) = X_1(i) \oplus X_2(i) \oplus X_r(i) \oplus ... \)
- The machine can even keep running with disk failure, because we could do the parity computation on the fly.
- Very high transfer rates for big moves.
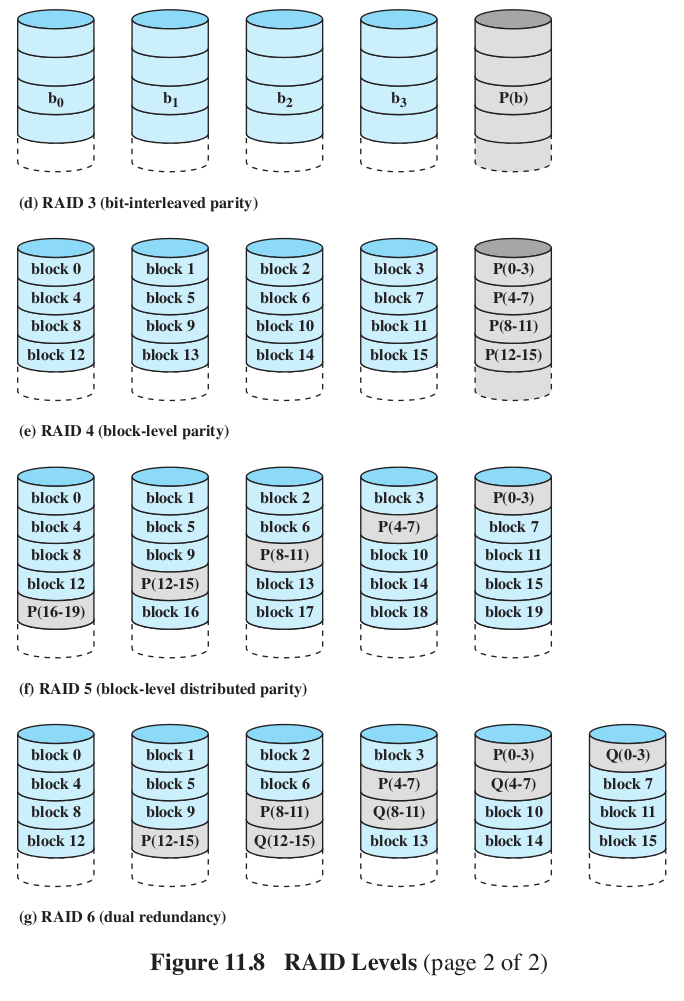
- Level 4:
- Make the strips bigger. That's it.
- Level 5:
- Distribute the parity, so we don't have to write to the same parity disk every time we write.
- Level 6:
- Like 5, but now with two parity checks per bit.
- one is xor
- The other is more complex, essentially encryption.
- Can reconstruct the data even with the loss of 3 disks.
- Just like a RAM cache, but for disks.
- Locality!
- The question we always ask is, what disk sector gets swapped out?
- Least Recently Used. Sound familiar?
- Least Frequently Used. Keep a count of the references. Move out the one with the smallest number.
- LFU has a problem- if a block is used in burst (many accesses in a row, followed by long periods of inactivity) then the counts will still be high enough to keep it from being swapped out, even though it is not going to be used in a while.
- Solution: only increment counters if it has not recently been incremented.
- Special files are associated with each device. You can read and write from them like a file.
- Two kinds of devices- Character and block. character devices have no caching, block devices do. Many can be opened in either mode.
- There are 3 disk schedulers: the Elevator Scheduler (a variation of LOOK), Deadline Scheduler, and Aniticipatory I/O.
- Elevator:
- if new request is same or adjacent to something on the queue, merge the two
- If any request on the queue is older than a threshhold, new requests are added to tail.
- Else, place in sorted order,
- Deadline:
- 2 above addresses starvation, but not super effective (wrong pokemon type? No, write requests (which no one blocks on, could crowd out read requests)
- New requests are put in either a FIFO read queue or FIFO write queue, plus the elevator queue.
- Each request has a deadline- 5 second fro write, 0.5 for read.
- Normally select job from Elevator, but if head of either FIFO queue has expired, then select from it.
- Anticipatory
- If process is reading with short delays, we might jump to servicing another request, and then come back to to this read, which was close to where we were before.
- When a read request is dispatched from the FIFO read queue, the scheduling system pauses for 6ms afterthe read to see if anything else is coming from that process.
- A little surprising that it is super effective.