
You're a historian who uncovered old transcripts from an unknown author. You want to align these texts with known authors and see if you can predict how likely they are to have come from them. This is actually a real task that real social scientists investigate. Some of Shakespeare's works are questioned as coming from him or not. In American Revolutionary times, people frequently published under pseudonyms to hide their identities, and we can use automated techniques to show similarities between known authors and their unattributed pieces of work. You can imagine modern day usefulness too, such as aligning anonymous social media posts with real people.
In this 2-part lab, you will process snippets from real novels with real authors, and then you will see if you can write a program to predict who wrote other unattributed snippets. For the purposes of this lab, we know who wrote all the snippets, and you will simply test against the correct answers.
Download the training novels, test novels, and short example snippets
Or just copy/paste this command into your Ubuntu shell:
curl -O https://www.usna.edu/Users/cs/nchamber/courses/forall/lab/l09/train-snippets.tsv -O https://www.usna.edu/Users/cs/nchamber/courses/forall/lab/l09/ten-snippets.tsv -O https://www.usna.edu/Users/cs/nchamber/courses/forall/lab/l09/short-snippets.tsv
Install the NLTK package to help with text processing:
sudo apt install python3-nltk
Our approach is to count words in each piece of text, and then compare the vector of word counts against an author's known texts. We'll find the best matching vector of word counts, and declare that to be the original author.
Shakespeare: "I do hate proud men as I do hate the engend'ring of toads."
Dickens: "The candle was burning low in the socket as he rose to his feet."
Unkown: "He was, altogether, as roystering and swaggering a young gentleman as ever stood four feet six."
Who wrote the last one? If you look at just word overlap ... we see more blue words matching Dickens ... which in this case is correct! In today's lab, you will write a program to do this word comparison automatically.
The key to your approach will be counting words! You can view each piece of text as a vector of word counts. See the counts below:
| I | do | hate | proud | men | as | the | engend'ring | of | toads | candle | was | burning | he | ... | four | feet | six | |
| Shakespeare | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 |
| Dickens | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | ... | 0 | 1 | 0 |
| Unknown | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | ... | 1 | 1 | 1 |
You will hold these counts in a Dictionary, of course. Each piece of text will have its own Dictionary of word counts. The keys are the words, and the values are the counts of each word. Above in blue are the words that appeared in more than one text, showing you the overlap. We'll use a metric to compare vectors for similarity, thus matching authors with their text.
Create a file part1-read.py
The first step is to read text and store their word counts in a Dictionary.
Write a program that reads a file of text snippets (and their authors), and converts each snippet to a Dictionary of word counts. We had a homework which counted characters. You will now count words instead of characters. Use the NLTK library to help you split sentences into words:
import nltk
tokens = nltk.word_tokenize("I just can't even, for real.")
print(tokens) # Prints: ['I', 'just', 'ca', "n't", 'even', ',', 'for', 'real', '.']
One thing we don't want to do is count common words like 'the' and 'a'. The NLTK library helps us out because it comes with a handy-dandy "stop words list" for English. You can access it like this:
from nltk.corpus import stopwords
nltk.download('stopwords')
nltk.download('punkt')
# a List of words which you should use to NOT count
stops = stopwords.words('english')
Requirements:
Your output when running your program on short-snippets.tsv should look like this but your words will be in a different order when printed (that's ok, but counts should match!).
WARNING: you might discover on your own that NLTK has an object called FreqDist which counts words for you. We have not yet learned how to properly use new class types like this, so you are not allowed to use it in this lab.
Copy your Step 1 code to part2-user.py
Let's build on Step 1 and write a program that matches user text to their most similar author! The user will type in a sentence or two, and you'll tell them which author they are most like.
In order to do this, we will use your function that creates a Dictionary of word counts. We just need a mechanism of comparing two Dictionaries, right? That's how we'll compare the user's text to an author's text. As we said above, you can think of these dictionaries as vectors where the cells are counts of words in English. Here is the Dickens text with the Unknown text again:
| I | do | hate | proud | men | as | the | engend'ring | of | toads | candle | was | burning | he | ... | four | feet | six | |
| Dickens | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | ... | 0 | 1 | 0 |
| Unknown | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | ... | 1 | 1 | 1 |
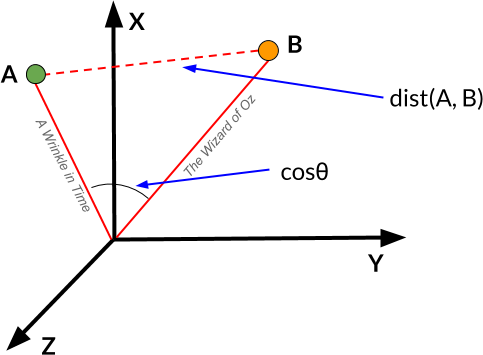
You can see they both contain the words 'as', 'was', 'he', and 'feet'. Would you conclude that these two vectors are similar? How similar? How do we decide in a quantifiable way? Well we need a type of similarity metric that calculates the distance/similarity between two vectors. There are several options for this, such as Euclidean distance (dist(A,B) in the image at right) or computing the cosine of the angle between them (cos(theta) in the image).
Cosine similarity is commonly used because it normalizes the lengths of the vectors, which is a good thing. The smaller the angle, the more word overlap between the texts. Cosine similarity ranges from 1 (perfect word overlap) to 0 (no overlap). We are not requiring you to write this function, so instead I wrote it for you. Download the file at the link, and import it into your program!
import si286
d1 = dict()
d2 = dict() # make sure to fill these, of course, with word counts
...
simscore = si286.cosine_sim(d1,d2)If you have two dictionaries of word counts, you just call my cosine_sim() function as above, and it will give you the similarity score between two word vectors (two dictionaries of word counts).
Your task in this part is to read all texts from the file, convert them to Dictionaries, and then ask the user for a sentence. Find the best matching author to the user's sentence.
Requirements:
Required Output: (you don't need it to loop, can just run on one input and then stop)
Passage: The night is dark and full of terrors. Most similar: SHAKESPEARE Than death and honour. Let's to supper, come, And drown consideration. Exeunt ACT_4|SC_3 SCENE III. Alexandria. Before CLEOPATRA's palace Enter a company of soldiers FIRST SOLDIER. Brother, good night. To-morrow is the day. SECOND SOLDIER. It will determine one way. Fare you well. Heard you of nothing strange about the streets? FIRST SOLDIER. Nothing. What news? SECOND SOLDIER. Belike 'tis but a rumour. Good night to you. FIRST SOLDIER. Well, sir, good night. [They meet other soldiers] SECOND SOLDIER. Soldiers, have careful watch. FIRST SOLDIER. And you. Good night, good night. [The two companies separate and place themselves in every corner of the stage] SECOND SOLDIER. Here we. And if to-morrow Our navy thrive, I have an absolute hope Our landmen will stand up. THIRD SOLDIER. 'Tis a brave army, And full of purpose. [Music of the hautboys is under the stage] SECOND SOLDIER. Peace, what noise? THIRD SOLDIER. List, list! SECOND SOLDIER. Hark! THIRD SOLDIER. Music i' th' air. FOURTH SOLDIER. Under the earth. THIRD SOLDIER. It signs well, does it not? FOURTH SOLDIER. No. THIRD SOLDIER. Peace, I say! What should this mean? SECOND SOLDIER. 'Tis the god Hercules, whom Antony lov'd, Now leaves him. THIRD SOLDIER. Walk; let's see if other watchmen Do hear what we do. SECOND SOLDIER. How now, masters! SOLDIERS. [Speaking together] How now! How now! Do you hear this? FIRST SOLDIER. Ay; is't not strange? THIRD SOLDIER. Do you hear, masters? Do you hear? FIRST SOLDIER. Follow the noise so far as we have quarter; Let's see how it will give off. SOLDIERS. Content. 'Tis strange. Exeunt Passage: It is not down on any map; true places never are. Most similar: SHAW CATHERINE (relenting). Ah! (Stretches her hand affectionately across the table to squeeze his.) PETKOFF. And how have you been, my dear? CATHERINE. Oh, my usual sore throats, that's all. PETKOFF (with conviction). That comes from washing your neck every day. I've often told you so. CATHERINE. Nonsense, Paul! PETKOFF (over his coffee and cigaret). I don't believe in going too far with these modern customs. All this washing can't be good for the health: it's not natural. There was an Englishman at Phillipopolis who used to wet himself all over with cold water every morning when he got up. Disgusting! It all comes from the English: their climate makes them so dirty that they have to be perpetually washing themselves. Look at my father: he never had a bath in his life; and he lived to be ninety-eight, the healthiest man in Bulgaria. I don't mind a good wash once a week to keep up my position; but once a day is carrying the thing to a ridiculous extreme. CATHERINE. You are a barbarian at heart still, Paul. I hope you behaved yourself before all those Russian officers. PETKOFF. I did my best. I took care to let them know that we had a library. CATHERINE. Ah; but you didn't tell them that we have an electric bell in it? I have had one put up. PETKOFF. What's an electric bell? CATHERINE. You touch a button; something tinkles in the kitchen; and then Nicola comes up. PETKOFF. Why not shout for him? CATHERINE. Civilized people never shout for their servants. I've learnt that while you were away. Passage: Some hae meat and canna eat, -- And some wad eat that want it; But we hae meat, and we can eat, Sae let the Lord be thankit. Most similar: CONRAD chance--barring, of course, the killing him there and then, which wasn't so good, on account of unavoidable noise. But his soul was mad. Being alone in the wilderness, it had looked within itself, and, by heavens! I tell you, it had gone mad. I had--for my sins, I suppose--to go through the ordeal of looking into it myself. No eloquence could have been so withering to one's belief in mankind as his final burst of sincerity. He struggled with himself, too. I saw it,--I heard it. I saw the inconceivable mystery of a soul that knew no restraint, no faith, and no fear, yet struggling blindly with itself. I kept my head pretty well; but when I had him at last stretched on the couch, I wiped my forehead, while my legs shook under me as though I had carried half a ton on my back down that hill. And yet I had only supported him, his bony arm clasped round my neck--and he was not much heavier than a child. "When next day we left at noon, the crowd, of whose presence behind the curtain of trees I had been acutely conscious all the time, flowed out of the woods again, filled the clearing, covered the slope with a mass of naked, breathing, quivering, bronze bodies. I steamed up a bit, then swung down-stream, and two thousand eyes followed the evolutions of the splashing, thumping, fierce river-demon beating the water with its terrible tail and breathing black smoke into the air. In front of the first rank, along the river, three men, plastered with bright red earth from head to foot, strutted to and fro restlessly. When we came abreast again, they faced the river, stamped their feet, nodded their horned heads, swayed their scarlet bodies; they shook towards the fierce river-demon a bunch of black feathers, a mangy skin with a pendent tail--something that looked like a dried gourd; they shouted periodically together strings of amazing words that resembled no sounds of human language; and the deep murmurs of the crowd, interrupted suddenly, were like the response of some satanic litany.
Copy part2-user.py to part3-batch.py
Your last program will now do full text matching, not from a user's small input. Instead you will read UNKNOWN texts from a file, and print out the best matching author. It's similar to Step 2, but you'll be looping over a file of unknown texts instead of reading one sentence from a user input.
Requirements:
Required Output: (except for the '# wrong')
Test Filename: ten-snippets.tsv
File contains 10 lines.
HAWTHORNE # wrong (Eliot)
JAMES
SHAKESPEARE
DICKENS
AUSTEN # wrong (Eliot)
AUSTEN
TWAIN
CONRAD
AUSTEN
HAWTHORNE # wrong (Hardy)
This rudimentary approach works fairly well! 7/10 correct if you matched our output. Next week we will explore some other approaches.
Visit the off-Yard submit website and upload your THREE programs.