- State Minimization: The Problem
-
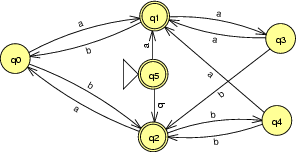
Consider the machine M1 below:
If you look at it a bit, you should be able to convince
yourself that you could redesign it to use fewer states to
accept the same language. Why? Well states q3 and
q6, for example, essentially do the same thing.
Couldn't they be merged into a single state? This same
observation applies in a couple of other places.
In fact, this situation of having a machine with more states
than it needs crops up all the time, since we have so many
algorithms for combining and converting machines, and these
algorithms often use more states than are necessary for
specific inputs. This is especially true of our algorithm
for converting a nondeterministic finite automaton without
e-transitions to a deterministic finite automaton,
which was a key ingrediant in the process of converting a
regular expression into a computer program that searches for
matches to that expression. So, we would like to have an
algorithm that takes a DFA M as input, and returns
another DFA M' that accepts L(M) and has
as few states as is possible for a DFA accepting L(M).
- An example of the Algorithm for Minimization
-
The basic idea of the state minimization algorithm is
to group together states that are "essentially the same".
We take a stab at a grouping, test it, and based on the tests
either conclude that we're done or split up our groups further.
At each step, we want to make sure that two states are in
different groups only if we're absolutely sure they
cannot be considered essentially the same.
To be conservative, we start off splitting the states into two
separate groups: the accepting states and the nonaccepting
states. These two groups are definitely different, because
ending up in one is very different from ending up into the
other.
The key property that we need to hold in each group is that
every state in group Gi should agree on which group
to transition to for each character. For example,
if q1 and q3 are both in G1, δ(q1,a)
δ(q3,a) have to go to states in the same
group. They don't have to go to the same states, they just
need to go to states in the same group. When this property
doesn't hold, we need to split up our group into subgoups
in which the property does hold. Doing this splitting over
and over until there's no need to split further is the
algorithm! Below is an example of performing this procedure
on M1:
| a b
-------------
G1 q0| G1 G1
q1| G1 G2 ← Split into
q2| G1 G2 new group G3
q3| G1 G1
q6| G1 G1
|
G2 q4| G2 G1
q5| G2 G1
|
|
| a b
-------------
G1 q0| G3 G3 ← Split into
q3| G1 G1 new group G4
q6| G1 G1
|
G2 q4| G2 G1
q5| G2 G1
|
G3 q1| G1 G2
q2| G1 G2
|
| a b
-------------
G1 q3| G1 G1
q6| G1 G1
|
G2 q4| G2 G1
q5| G2 G1
|
G3 q1| G1 G2
q2| G1 G2
|
G4 q0| G3 G3
|
Once we've found our grouping, we construct a new machine
whose states are groups and whose transitions are given by
the final table in the procedure above:
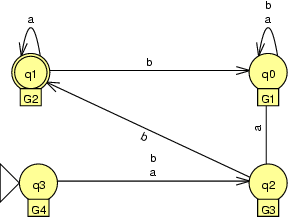 Now instead of a machine with 7 states we have a machine
with 4 states.
Now instead of a machine with 7 states we have a machine
with 4 states.
- A Precise algorithm
-
Given a machine M = (Q,Σ,δ,s,W)
we want to construct a machine M' that has fewer
states (if possible) and accepts L(M).
To make a nice-looking, precise algorithm out of the above
procedure we need a few definitions:
Suppose the elements of Q are partitioned into sets
G1,...,Gn. Then define δG
as:
δG(q,x) = Gi
such that δ(q,x) ∈ Gi.
For Σ = {a1,a2,...,am}, define the signiture
sig of state Q as:
sig(q) =
(δG(q,a1), δG(q,a2),
..., δG(q,am))
So δG(q,x) gives the entries of the
table we used in the previous section, and sig(q)
gives whole rows of the table.
Here's the algorithm for dividing the states into groups of
equivalent states:
- set G1 = Q - W and G2 = W
-
For each group Gi, divide Gi into
subgroups in which sig(q) is the same
for every state q.
- if any group was subdivided, go back to (2) and repeat
Once you have the groups G1,...,Gn, the machine
M' = ({G1,...,Gn},Σ,δG ,s',W')
where
s' = Gi where s ∈ Gi, and
W' = {Gi | Gi ∩ W ≠ ∅}.
- Finite Automata & Regular Expression Debrief
-
We've looked at three basic kinds of languages so far:
languages accepted by deteministic finite automata, languages
accepted by nondeterministic finite automata, and languages
defined by regular expressions. What we've proved is that all
three classes of languages are in fact the same class, and we
refer to this class of languages as regular languages.
Regular languages are theoretically interesting because they
are the languages that can be accepted by machines (or
programs) with a fixed amount of memory. They are
interesting in practice because they are the languages for
which we have a simple, efficient pattern matching algorithm
through our regular expression to NDFA to DFA to program
pipeline, and pattern matching is a problem of tremendous
practical importance.
We've also seen, thanks to the Pumping Lemma, that there are
many languages that are not regular, meaning that they
cannot be accepted by a machine with a fixed amount of
memory. Our next step will be to augment our machine model
with a simple form of auxilliary memory and to see if any of
these languages will be acceptable by augmented machines.
In the background of our investigations has been this whole
methodology of modelling machines with tuples, sets and
functions, and of proof by algorithm. When we explore these
new augmented machines we'll be using all the same
techniques, which'll hopefully be a lot easier to follow the
second time around.