points that are its vertices, and in the context I
have in mind, I'll also give each quadrilateral a character that
acts as a label. The struct for quadrilateral, which I'll call
Quad, has the following simple definition:
struct Quad
{
char label;
point *vert;
};
Here's a simple main() using the struct. All it does is
read in a Quad and print it back out again. Notice
how I create an object of type Quad. It takes two
steps, one actually creates the Quad object, and one
allocates the array of four points that stores the vertices.
int main()
{
// Create quadrilateral S
Quad S;
S.vert = new point[4];
// Read label and vertices
cout << "Enter label and 4 vertices: ";
cin >> S.label;
for(int i = 0; i < 4; i++)
cin >> S.vert[i];
// Write label and vertices
cout << "Your quadrilateral is " << S.label << " ";
for(int j = 0; j < 4; j++)
cout << S.vert[j] << ' ';
cout << endl;
return 0;
}
This gives us a pretty good look at how we've done things so far,
and you can look at the complete program
to make sure you see how all these pieces fit together.
point stuff, and the new code, which is the
Quad definition and the main function.
Furthermore, the point stuff falls into two obvious
pieces - the struct definitions & function prototypes, and the
function definitions.
Prototypes for point stuff |
New code - definition for Quad and
main |
Definitions for point-related functions |
#include <iostream>
#include <fstream>
using namespace std;
/*********************************************
** PROTOTYPES & STRUCT DEFINITIONS
*********************************************/
struct point
{
double x, y;
};
void read(point &p, istream &IN);
void write(point p, ostream &OUT);
point operator+(point a, point b);
point operator/(point P, double z);
ostream& operator<<(ostream& OUT, point p);
istream& operator>>(istream& IN, point &p);
|
struct Quad
{
char label;
point *vert;
};
int main()
{
// Create quadrilateral S
Quad S;
S.vert = new point[4];
// Read label and vertices
cout << "Enter label and 4 vertices: ";
cin >> S.label;
for(int i = 0; i < 4; i++)
cin >> S.vert[i];
// Write label and vertices
cout << "Your quadrilateral is " << S.label << " ";
for(int j = 0; j < 4; j++)
cout << S.vert[j] << ' ';
cout << endl;
return 0;
}
|
/*********************************************
** FUNCTION DEFINITIONS
*********************************************/
void read(point &p, istream &IN)
{
char c;
IN >> c >> p.x >> c >> p.y >> c;
}
void write(point p, ostream &OUT)
{
OUT << '(' << p.x << ',' << p.y << ')';
}
point operator+(point a, point b)
{
point S;
S.x = a.x + b.x;
S.y = a.y + b.y;
return S;
}
point operator/(point P, double z)
{
point Q;
Q.x = P.x / z;
Q.y = P.y / z;
return Q;
}
ostream& operator<<(ostream& OUT, point p)
{
write(p,OUT);
return OUT;
}
istream& operator>>(istream& IN, point &p)
{
read(p,IN);
return IN;
} |
point.h,
main.cpp, and
point.cpp.
Now, to use the struct point and all of its
related functions, we really only need the function prototypes and struct
definition - the definitions of the functions don't really
concern us as users of point. We only care about
what's available for us to use, not how it works. So, the file
main.cpp begins with the
line:
#include "point.h"which means literally pretend that the entire contents of
point.h was typed in starting at this point.
Thus, as far as the compiler is concerned, it's like that struct
definition and all those prototypes were right there.
You'll notice that point.cpp
also begins with #include "point.h", since those
function definitions won't make sense to the compiler without
the definition of the struct point and the prototypes.
So, your compiler views your program as consisting of two files,
main.cpp and
point.cpp, both of
which use point.h.
It's perfectly willing to compile point.cpp, saying
"I believe there is a main function somewhere
that's going to use these function definitions.
And the compiler is perfectly willing to compile
main.cpp saying "I believe there are some .cpp
files somewhere that define these functions that
main uses and whose prototypes are given in the
included file point.h. Then, when the program is
linked, these two compiled pieces are brought together (along
with any standard library code we need) to form a complete
program.
Breaking programs up into separate files this way doesn't really
change what you can or can't do, but it makes it much easier to
organize your code, and it makes it much easier to reuse
structs and functions from previous programs. In fact, your
start thinking of big programs as different modules to write:
each module containing a .h file (or
header file) that gives the outside world all the
information it needs to use the module, and a
.cpp file that contains the source code that
implements the module (i.e. that tells the compiler how all
these functions really work). What you saw up above was a very
simple point module. One key thing that's missing
from my simple point module, however, is documentation. The
header file needs a lot of documentation so that the user
of the module understands how to use the struct and the various
functions the module offers. They don't need to know
how it works, but they do need to know what it
does!
The other kind of array is static A static array has its size determined when the program is compiled, so from run to run of the program the array's size is always the same. A static array wouldn't work for a program that reads in data from a file that contains an unknown amount of information. How big should you the programmer make the array? You don't know. Dynamic arrays are more general - anything you can do with static arrays you can do with dynamic arrays, and then some. However, in some instances static arrays are simple - for example if you wanted to hardcode the names of the days of the week into a program. You know the size will be 7, so there's no point in making a dynamic array.
The syntax for creating a static array is a little bit different than for creating a dynamic array.
Creating an Array of 6 ints |
|
| Static Array | Dynamic Array |
int A[6] |
int *A = new int[6] |
Using the array after its been created is pretty much the same
for either. One difference is that if A is a
static array, the pointer A cannot be changed. The
contents of the array to which it points can, of course, be
changed. But not the pointer itself. Other differences are
best illustrated by an example.
The above program uses arrays to store the vertices of a quadrilateral. Since we know that a quadrilateral always has exactly four vertices, we could use static arrays.
struct Quad
{
char label;
point vert[4];
};
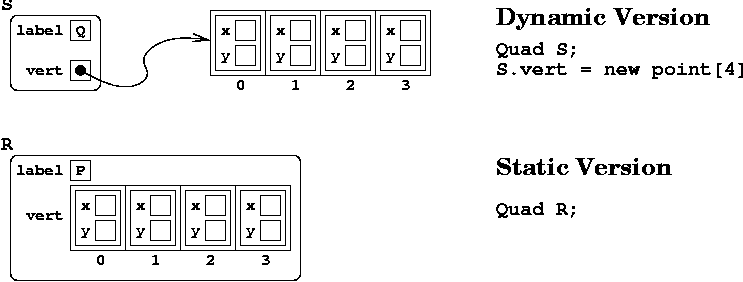
To understand the difference between this version of
Quad and the previous version, consider this picture:
You see that in the static array version the array of vertices is
embedded in the Quad object. In the dynamic version,
the pointer is embedded in the object, while the array is outside
of the object, somewhere else in memory.
Compare the static array version of main
with the dynamic array version of main.
The above picture really tells you all you need to know to
understand the difference between using static and dynamic
arrays ... when you really can use static arrays. Let's look at
one example to see what consequences arise from this picture.
Suppose that I have a Quad object S
that contains the label 'Q' and the vertices
(0,0) (1,0) (1,1) (0,1). Then suppose we run the following
code:
Quad R; R = S; R.label = 'P'; for(int i = 0; i < 4; i++) R.vert[i] = R.vert[i].x + 1;So, I create a copy of
S, which I call
R. I then add one to the x-coordinate of each vertex
of R. Suppose I then print out S and
then I print out R. What will I get?
Well, it depends whether I'm using the static version of
Quad or the dynamic version:
| Static Version | Dynamic Version | Q (0,0) (1,0) (1,1) (0,1) P (1,0) (2,0) (2,1) (1,1) |
Q (1,0) (2,0) (2,1) (1,1) P (1,0) (2,0) (2,1) (1,1) |
Why the difference? Look at the picture!
| Dynamic Version | Static Version |
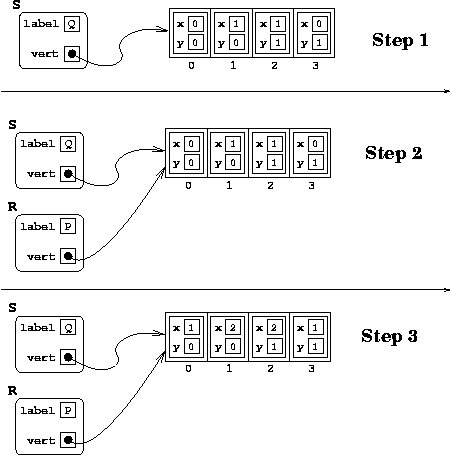
|
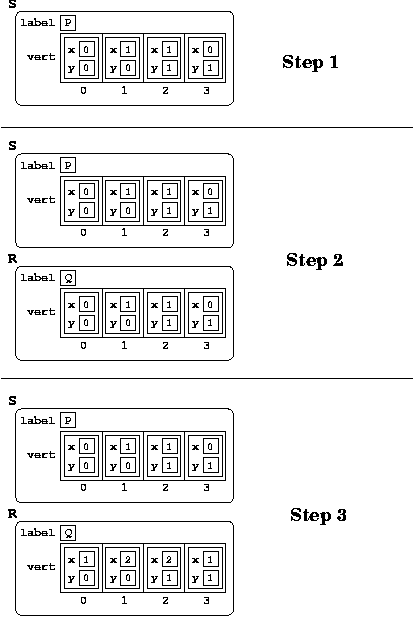
|
This is not a reason to use static over dynamic, but it is a good
example of how and why they behave differently. Here's another
example: how does swap(A,B) behave differently for
two Quads, A and B,
with the dynamic versus static array versions of
Quad? Once again, the picture should tell you that
while the result it the same, a lot more work gets done in the
static case, where the entire contents of the arrays are swapped,
rather than simply the pointers.
point struct and a
struct hhmmss. Break the program up into separate
point and hhmmss modules, and of
course a main file. We have the following pieces:
datum, but it seems less likely to be reused, so
there's a less compelling reason for doing it.
int prime[10] = {2,3,5,7,11,13,17,19,23,29};
Note: this is purely about static arrays, it doesn't
concern structs at all.
Here's my solution.