Stept 1: int *p, x = 2; Stept 2: p = new int; Stept 3: (*p) = x + 1;
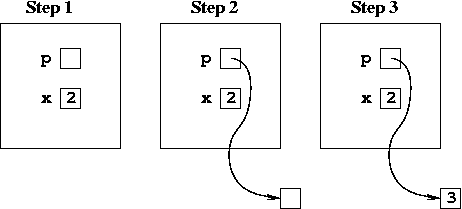
You can allocate a single object of a given type by just leaving
the square brackets off the new statement. For example, to
create a single int object and a pointer,
p, that points to it, we could write:
int *p = new int;To delete the
int that p points to, you
use the usual delete statement, except without the
square brackets. So to delete the int that
p points to, you would write:
delete p;Now, it turns out that you can treat
p as an array
containing just one int, in the sense that
p[0] does indeed give you the int that
p points to. However, when we have a pointer to a
single object, we usually use an asterisk (*) to get the object from
the pointer. This is called dereferencing the pointer.
The syntax is *p, which evaluates to the object
p points to. So, for example, to allocate a single
int using new, and then to assign that
int a value we might do something like this:
Stept 1: int *p, x = 2; Stept 2: p = new int; Stept 3: (*p) = x + 1; |
|
p is a pointer to an
int, while *p is the actual int that
p points to.
Now, when the objects you allocate are classes, the * for
dereference can get a little ugly. For example, consider our ever
polular struct point:
struct point
{
double x, y;
};
We allocate a single object of type point and intialize its x and
y coordinates to zero with the following code:
point *ptr = new point; (*ptr).x = 0; (*ptr).y = 0;This syntax is a little bit ugly ... maybe even more than a bit. Therefore, the inventors of the C language (from which C++ is derived) decided to provide a shorthand notation for accessing a data-member of a struct from a pointer: the
->
operator. The pointer goes on the left, the name of the data
member goes on the right. So the above example becomes:
point *ptr = new point; ptr->x = 0; ptr->y = 0;Remember, this is just a shorthand to make things easier for programmers to write and easier to read.
Note: A pointer can also point to a local variable
(i.e. one that was declared rather than allocated with
new), although this has very little utility
in C++ (there's one exception that comes up in data structures,
but for the most part pointers to local variables is a relic of C).
In order to get a pointer to an object from the object itself,
you use the & operator. Don't let the fact that
this symbol is also used for pass-by-reference confuse you!
The expression &name evaluates
to a pointer to the variable name. The
& is called the "address-of operator".
So,
for example:
int *p, x; p = &x; (*p) = 3; cout << x << endl;will print out "3". The second line sets
p to point
to the int x. This third line sets the
"int pointed to by p" (which is x) to 3.
struct Character
{
Pos myloc;
Pos *homePtr;
};
int *p; ← this is a declaration, so the * means pointer declaration *p = 7; ← *p is an expression and the * is used as a unary rather than binary operator, so the * means cout << 3*7; ← 3*7 is an expression, and the * is used as a binary operator, so the * means multiplicationAs a nice treat, figure this out:
int * q = &(x = 2 * * p);
Cool, eh? All three uses of * in one statement!
void foo(int & x); ← this is a declaration, so the & means pass-by-value int * p = &x; ← &x is an expression, so the & means address-of (or pointer-to)
char *S; double **A; int n;
| expression | type |
| *S | char |
| &S | char** |
| *A | double* |
| &A | double*** |
| *n | error! |
| &n | int* |
new, so you always have to know
how many objects you want to store ahead of time.ints
that data would be an int, in a linked list of
strings that data would be a string, etc)
and a link to the "next" node in the list. The following picture
shows a linked list storing the numbers 87, 42, 53, 4.

LIST" in the picture. From there you simply
follow the links (arrows) from one piece of data to the next.
The last node in a linked
list does not have a link to a "next" node - we usually show
its next-field with a slash to indicate that.
To realize this picture in C++ code, we see that we have to
manipulate "nodes". Therefore, it's natural to make a struct
Node. Let's assume that we want to store strings
in our list, then a Node will consist of a string,
which we might call "data", and a link to the "next" node. The
question is, what type of object would the link to the "next"
node be? Hopefully you see that what we need is a
pointer to the next node in the list, which means we
need a pointer to an object of type Node - i.e. we
need a data member of type Node*.
struct Node
{
string data;
Node* next;
};
Note: by convention, the next field of the
last element in the list is set to the value NULL
to indicate that it's not pointing to anything. This is often
called a "null pointer".
Node like:
struct Node
{
int data;
Node* next;
};
Now, we might have a variable of type Node* called
LIST that points to the first node in our linked list
of integers. Our list might look something like this:
We could print out the first integer in our list with the statement
cout << LIST->data;which says "print the
data field of the
Node pointed to by LIST". You can
simply follow that in the picture, it prints out 87. Now, to
print out the second integer in the list, we'd like to say the
same thing, except instead of LIST, which points to
the first node in the list, we need a pointer to the
second node in the list. Then we could write:
cout << (pointer to the second node)->data;Now, if you look back at the picture, you see that there is a pointer to the second node in the list, it is the
next field from the first node in the list, i.e.
LIST->next is a pointer to the second node in the
list. So, to print out the second node in the list you write:
cout << (LIST->next)->data;Actually you don't need the parentheses, because the
-> is left associative. Anyway, to print out the
third element of the list you could write:
cout << LIST->next->next->data;On the other hand, this way lies madness! It's usually better to simply make a temporary pointer that points to what you want, and move that pointer through the list. For example:
Node* ptr = LIST; // Set ptr to point to first node ptr = ptr->next; // Set ptr to point to second node ptr = ptr->next; // Set ptr to point to third node
Node, set it's
data and next fields, and set
LIST to point to it, since it's supposed to be the
new "first node in the list". The following picture shows it all:
| Initially we have: |  |
Node *temp = new Node; |  |
temp->data = 8; |  |
temp->next = LIST; |  |
LIST = temp; |  |
| At the end we have: |  |
val to the
front of a
linked list LIST, the same sequence of steps will
do the job:
Node *temp = new Node; temp->data = val; temp->next = LIST; LIST = temp;
In our programs, we represent an empty list by a null pointer,
i.e. with a pointer whose value is NULL. Once you accept
the empty list, lots of things become a bit easier to discuss.
For example, the sequence of steps we used to add a new
element to the front of a list works perfectly well even when
the list is empty. In the example below, LIST is
empty, and the exact same sequnce of steps we used above will
add the new value 3 to the "front" of the list:
| Initially we have: | |
Node *temp = new Node; | |
temp->data = 3; | |
temp->next = LIST; | |
LIST = temp; | |
| At the end we have: |
LIST pointer, then
the function better take the pointer to the front of the list
by reference! Of course, the function will also need to
be passed the value val that's supposed to be the
data for the new node.
void add2front(int val, Node* &LIST)
{
Node *temp = new Node;
temp->data = val;
temp->next = LIST;
LIST = temp;
}
Here is an example program that reads ints
from the user and stores them in a linked list using the
add2front function.
data fields of
the nodes in a linked list are pretty much irrelevant to the
problem of how to manipulate a list. Therefore, we're going
to concentrate on basic linked list manipulations, which
provide us with a wealth of interesting problems. These
typically boil down to functions you'd like to define, like: