Reading
None.
Linked list basics: traversing a list
This whole lecture is simply about looking at typical linked
list problems and how they're solved.
Both in the problem discussed in detail in the notes, and in
the problems given at the end of the notes, we look at both
iterative (i.e. using loops!) approaches and recursive approaches.
We'll start things off, however, by looking at the simplest of
programs: read and store ints in a linked list, then print
the values stored in a list.
Printing a list, and indeed most things you do with a linked
list, involves traversing a list — which means
visiting each node in the list, in order.
Doing this iteratively (as opposed to recursively, which we'll
see later) means using a temporary pointer that points to the
first node originally, then moves to point to the second node
in the list, then moves to point to the third, and so on.
Node *p = L;
while(p != NULL)
{
do whatever you have to do
p = p->next;
}
The last line of the while-loop body,
p = p->next; is what moves us from one node to
the next. Note that we can do this very compactly with a
for-loop like this:
for(Node *p = L; p != NULL; p = p->next)
do whatever you have to do
Now let's look at the concrete example of traversing the list in
order to print out its values.
#include <iostream>
using namespace std;
struct Node
{
int data;
Node *next;
};
void add2front(int val, Node* &L); |
int main()
{
// Create list
Node *L = 0;
int x;
while(cin >> x)
add2front(x,L);
// Print list
Node *T = L;
while(T != NULL)
{
cout << T->data << ' ';
T = T->next;
}
cout << endl;
return 0;
} |
void add2front(int val, Node* &L)
{
Node *T = new Node;
T->data = val;
T->next = L;
L = T;
} |
Note that you can write the while-loop for printing nice and
compactly as a for loop:
for(Node *T = L; T != NULL; T = T->next)
cout << T->data << ' ';
cout << endl;
I really prefer writing it this way, because it makes the
traversal code (the for(Node *T = L; T != NULL; T = T->next))
totally boiler-plate: that stays the same for any kind of list
you ever make, and really no matter what you're doing for the
traversal.
A typical linked list problem - compute the length
Here's a typical example of a linked list problem: Write a
function that determines the length of a linked list - i.e. the
number of nodes. Assuming that we have a Node class
like this:
struct Node
{
public:
int data;
Node *next;
};
we know that our function's prototype should look like this:
int length(Node*);
It returns an int because, of course, the length of a
list is an integer. It takes a pointer to a Node,
because we manipulate lists by manipulating pointers, just like
with arrays. The process we use to determine the length is
straightforward too: move through the list from front to back one
node at a time, keeping track of how many you visit in the
process.
int length(Node *L)
{
// Initialize: curr points to the node we're about to visit
Node *curr = L;
int count = 0;
while(????)
{
// record that we've visited the node pointed to by curr
count++;
// set curr to the next node to visit
curr = curr->next;
}
return count;
}
The only real difficulty is going to be this: How do we know when
we're done? What do we replace the
???? with?
The easiest way to determine this is to work through our current
function as it operates on an example list:
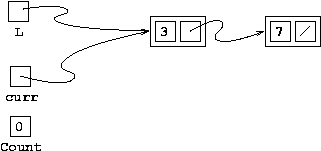
Before 1st loop iteration
Clearly we want to continue our iteration ... we haven't
even started yet! So, curr gets set to
curr->next, which leaves it pointing at the
second node, and count gets incremented,
showing that we've visited one node so far.
|  |
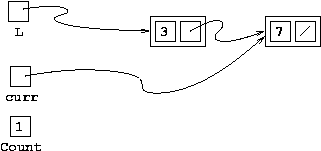
Before 2nd loop iteration
Noticing from the picture that we're pointing to the last
node in the list, you might be tempted to think that we
ought to stop now. However, curr is pointing
to the node we are about to visit, not the one
we just finished visiting. So, we haven't visited node 2
yet, and therefore should continue looping!
|  |
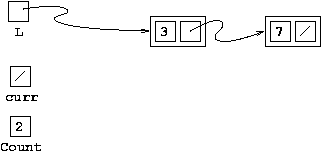
Before 3rd loop iteration
Now curr is the null pointer (i.e. pointer 0)
so there's no nodes left to visit. We've visited them all,
as count attests to, we we should exit our loop.
|  |
From the preceeding example, what was it that told us when we
should continue looping versus when it was time to stop? It was
the value of curr! Specifically, as long as
curr isn't the null pointer we should continue
looping! From this, we see that our function's completed
definition should be:
Of course we could also write the exact same code in a
for-loop, as discussed above. If we do, all the lines that
deal with the actual traversal of the linked list end up uin
the single "for" line.
int length(Node *L)
{
int count = 0;
for(Node *curr = L; curr != NULL; curr = curr->next)
{
// record that we've visited the node pointed to by curr
count++;
}
return count;
}
int length(Node *L)
{
// Initialize: curr points to the node we're about to visit
Node *curr = L;
int count = 0;
while(curr != NULL)
{
// record that we've visited the node pointed to by curr
count++;
// set curr to the next node to visit
curr = curr->next;
}
return count;
}
In general this way of writing functions for manipulating linked
lists is pretty good. It's usually questions like "when do we
stop this loop?" or "does this work with an empty list?" that
cause us problems. (Convince yourself that our
length implementation does work for the empty list!)
Try applying the same technique to the problems listed below.
A recursive approach to functions on lists
It turns out that a lot of linked list operations are very easily
accomplished with recursion. The reason for this is that there is
an essentially recursive way of looking at lists. Recall that "a
list" in our program is really a pointer to the first node in a
linked list. Suppose LIST is a variable of type
Node* in our program, and suppose that it points to
the list 87, 42, 53, 4 as illustrated in the following picture:

So, LIST is an object of type Node*
and therefore we say that it is a list. However, by that
same argument the next-field of the node with
data-value 87 is a list. After all, isn't it also of
type Node*? It is the list 42, 53, 4,
i.e. everything but the first element of the list that
LIST is. So, there is this natural way of
looking at a list as consisting of the first node and the list
of everything else.
As far as the length problem is concerned, we see
that the length of LIST is one plus
the length of the list given by the first node's
next pointer. So can't we say:
int length(Node *L)
{
return 1 + length(L->next);
}
Well, this almost works. It only "almost" work because our
recursive function has no base case. On the other hand, with
every recursive call the list we look at is smaller and smaller.
So we're naturally working towards the base case of a list of zero
elements - the empty list! Therefore, a complete recursive
function for computing the length of a list is:
int length(Node *L)
{
if (L == NULL)
return 0;
else
return 1 + length(L->next);
}
That's pretty elegant. Compare that to the "slick" way of doing
length iteratively:
int length(Node *L)
{
int count = 0;
for(Node *p = L; p != NULL; p = p->next)
count++;
return count;
}
Which one you prefer is a matter of taste. However, there are
some situations where the iterative approach is more natural and
some where the recursive approach is more natural. Try doing the
Problems below both ways.
P.S. Of course everything is cooler with the ?: operator:
int length(Node *L)
{
return L == NULL ? 0 : 1 + length(L->next);
}
Deleting a list
Since nodes in a linked list are each created dynamically with
"new", they live on in your program until they are
each individually destroyed with "delete". It is
often useful to have a function
void deletelist(Node* L); that deletes each of the
nodes in a list. In good ol' top-down fashion, I'll implement
this function "wishing" that other functions were available to me:
void deletelist(Node* L)
{
while(L != NULL)
deletefirstnode(L);
}
So, you see that the real problem is deleting the first node in a
list.
void deletefirstnode(Node* &L) // Assumes L is not the empty list!!
{
Node *T = L;
L = L->next;
delete T;
}
Hopefully you see that L = L->next effectively
removes the first node from L, but that to actually
give back the memory we allocated when creating that node with
new, we need to call delete.
Naturally, deletelist can be done recursively:
void deletelist(Node* L)
{
if (L == NULL)
return;
deletelist(L->next);
delete L;
}
Problems
- Find the maximum value in a list of
double's. Check out
my recursive and iterative solutions
- Construct a copy of a list of
double's. Check out
my recursive solution to this
problem. An iterative solution is tougher!
- Construct a reverse copy of a list of
double's. Check out
my iterative solution to this
problem. A recursive solution is tougher!