Suppose I used huffman coding to compress the following file (where each block is a 3-bit sequence):
010 010 010 010 010 010 010 111 010 111 010 110 010 110 010 010 010and then used Huffman coding again to compress the comressed file (once again using 3-bit sequences as blocks). Show me the two trees you used and the compressed and recompressed files. How much compression did you ultimately achieve? [Note: Be careful that your printer doesn't chop off some of the bit sequence above ... mine did.]
- Encoding Data
- There are many reasons for encoding data:
- Security RSA, DES, "0/1 Knapsack public key"
- Error Detection Checksum / parity bit
- Error Correction Redundancy, error-correcting codes.
- Compression Compression is either
lossless, meaning that compressing and
decompressing produces exactly the original file, or
lossy, meaning that compressing and
decompressing produces a file that is similar, though
perhaps not identical, to the original file.
Lossy Compression is used for graphics and audio formats. We as people don't need an exact reproduction of the orignal graphics/audio file. We're content with a similar file. A small amount of image/sound quality degradation is worthwhile if a much greater compression ratio is achievable as a result. Jpeg and Mpeg are examples of formats that use lossy compression.
Lossless Compression is the only option for general purpose compression. If you're compressing a program or a text document, even a single bit difference between the original and uncompressed file can be disasterous. We'll be talking about Huffman Encoding, which is the compression algorithm behind the Unix
packcommand. LZW is a more modern and generally better compression algorithm used in the Unixcompresscommand. It is also behind the GIF format, which is a lossless graphics format.
- Huffman Encoding
- Huffman encoding is a particular lossless compression
algorithm. It is a nice example of a greedy algorithm,
which is why we're talking about it at this point in the
course. Huffman Encoding looks at a file to be compressed
as a sequence of characters --- i.e. some fixed bit-length
block of information, like a byte of ASCII code. Each
character is encoded with its own particular code word,
but the codewords are not of fixed length. To recap:
Huffman Encoding encodes fixed-length characters with
variable lengthed code words. An example will probably
help.
Figure 17.3 from the book ------------------------- character "ASCII" frequency code-word a 000 45,000 0 b 001 13,000 101 c 010 12,000 100 d 011 16,000 111 e 100 9,000 1101 f 101 5,000 1100 Original File: badafedacaca | | V As ASCCII:001000011000101100011000010000010000 | | V Compressed: 1010111011001101111010001000 - Decompressing or Decoding
- Encoding is easy. Decoding is a bit trickier. The
problem is this: how do I recognize that a codeword has
ended? Sometimes this is very difficult. Consider the
following:
a -> 0 b -> 01 c -> 10
Now, if I try to decode010is it "ac" or "ba"? There's no way of knowing. The problem here is that the codeword for "a" is a prefix of the codeword for "b". Whenever one codeword is a prefix of another, we have this same ambiguity. Therefore we restrict ourselves to prefix codes, which are codes in which no codeword is a prefix of another.Assuming that our code is a prefix code, how can we decode? How can we decide whether the sequence of bits we've read so far is a codeword? The answer is this: We need a finite state machine that accepts codewords. Let's build one for the code from the previous example (which is a prefix code):
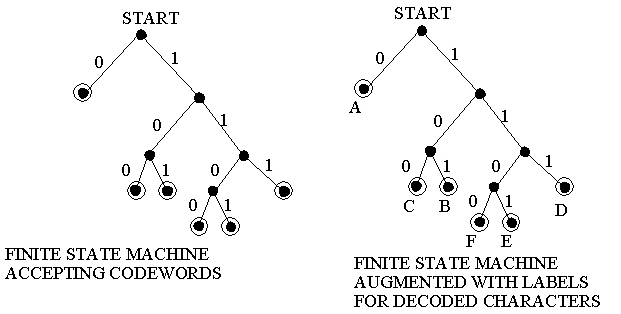
And if we want to not only recognize that a codeword has been read, but also determine which codeword, we need only add a tag to each accepting state in the finite state machine telling us which character we've just read. Of course, fancy finite state machines aside, this is a simple tree that we can build and use to decode encoded files. - The Tree
- Really, the tree (finite state machine) defines the
code. Each code defines a unique treee, and is uniquely
defined by a tree. So, what we want is this: Given a
file with characters {a1,...,ak}, each occuring with
frequency f(ai), construct a tree that produces a file of
minimum size.
We can do this via a greedy algorithm. But greedy algorithms require a problem that is posed as a series of choices to be made, and our tree construction problem doesn't look like that ... yet. Here's how we can pose the problem this way. We have a set of trees. As long as there is more than one tree, choose two trees and merge them, i.e. create a new node whose left child is the first tree and whose right child is the second tree. Initially, our set of trees will simply be the characters, each a tree of depth zero.
What's our "greedy choice" then? We always choose the two trees with lowest frequency to merge. That's the greedy algorithm behind Huffman encoding!
- The Greedy Algorithm is Optimal
- This greedy algorithm is optimal, in the sense that it
compresses the file as much as possible using the fixed bock
size. Here's a proof.
Given blocks/characters a1, a2, ..., ak, with frequencies f(a1), ..., f(ak), and we might as well assume that a1 and a2 are the two blocks with smallest frequencey. Any encoding that uses fixed block size is represented by a tree. Let T be a tree providing the most compression, and suppose that ai is a block at greatest depth in the tree. It's sibling must be another leaf node (otherwise we'd have a block at greater depth), let's call the block at that leaf node aj. For each block an, let d(an) be the depth of the leaf labeled an. The total size of the file compressed by T is:
f(a1)*d(a1) + f(a2)*d(a2) + ... + f(ak)*d(ak)
Now, our greedy algorithm merges a1 and a2 into a single tree as its very first step, which means that a1 and a2 are siblings in the final tree the greedy algorithm produces. Let's take the tree T, and swap a1 with ai and a2 with aj to create the tree T'. This would make a1 and a2 siblings. What does it do to the compression acheived by T'? Well, now the total size of the file compressed by T' is:f(ai)*d(a1) + f(aj)*d(a2) + ... f(a1)*d(ai) + ... + f(a2)*d(aj) + ... + f(ak)*d(ak)
... where the f's and the a's and the d's are all from T. Since d(ai) and d(aj) are the largest possible values of d, and since f(a1) and f(a2) are the smallest possible values of f, it's easy to see that T' produces a file that's no larger than that produced by T. So T' is an optimal tree, and lo an behold, block a1 and a2 are siblings, meaning that our greedy algorithm took the right step.